推理引擎的“蝴蝶效应” -- 从V32 模型的输出不一致说起
摘要
本文确认了 DeepSeek-V32 模型在输入长度为 4K的场景中 KV缓存 不一致并非输入或写入错误,而是稀疏化注意力(Sparse Atttenion)的输入的索引顺序不一致引发的输出差异,且该差异可在最小复现脚本中稳定复现。
背景
起因是排查推理引擎的一个异常现象:同一个长请求,在不同 DP(Data Parallel) 节点上得到的部分KV 缓存 ( KV Cache ) 不一致,在我们刻意关闭 batch 干扰、仅保留单请求和并行度 1 的情况下仍然复现,这个现象很不自然,于是我们决定把这条链路拆开,一段一段去验证精度问题。
实验方法和结果
仅 dump 结果,不对 topk 做矫正
针对 DeepSeek 模型,当前的计算逻辑可以简单拆分为 attn0(q_a/b_proj, bmm_wkc, kv_a_proj, rotary_emb计算)、attn1(mqa, bmm_wkv, o_proj 计算) 和混合专家 (MoE) 三大部分,因此实验的第一步是对每一层的 attn0 与 attn1 输出进行导出并做严格对比。

结果显示第 0 层的 attn0 可以做到 每个比特级别 (bitwise) 一致,而 attn1 不能做到完全一致,这一步直接把我们的归因的注意力集中到 attn1 内部的稀疏化注意力输出。为了让方法可复现,我们使用 diff_safetensors.py 对每一层的 attn0 与 attn1 输出做逐项对比,必要时输出差异窗口与直方图,脚本细节见附录。
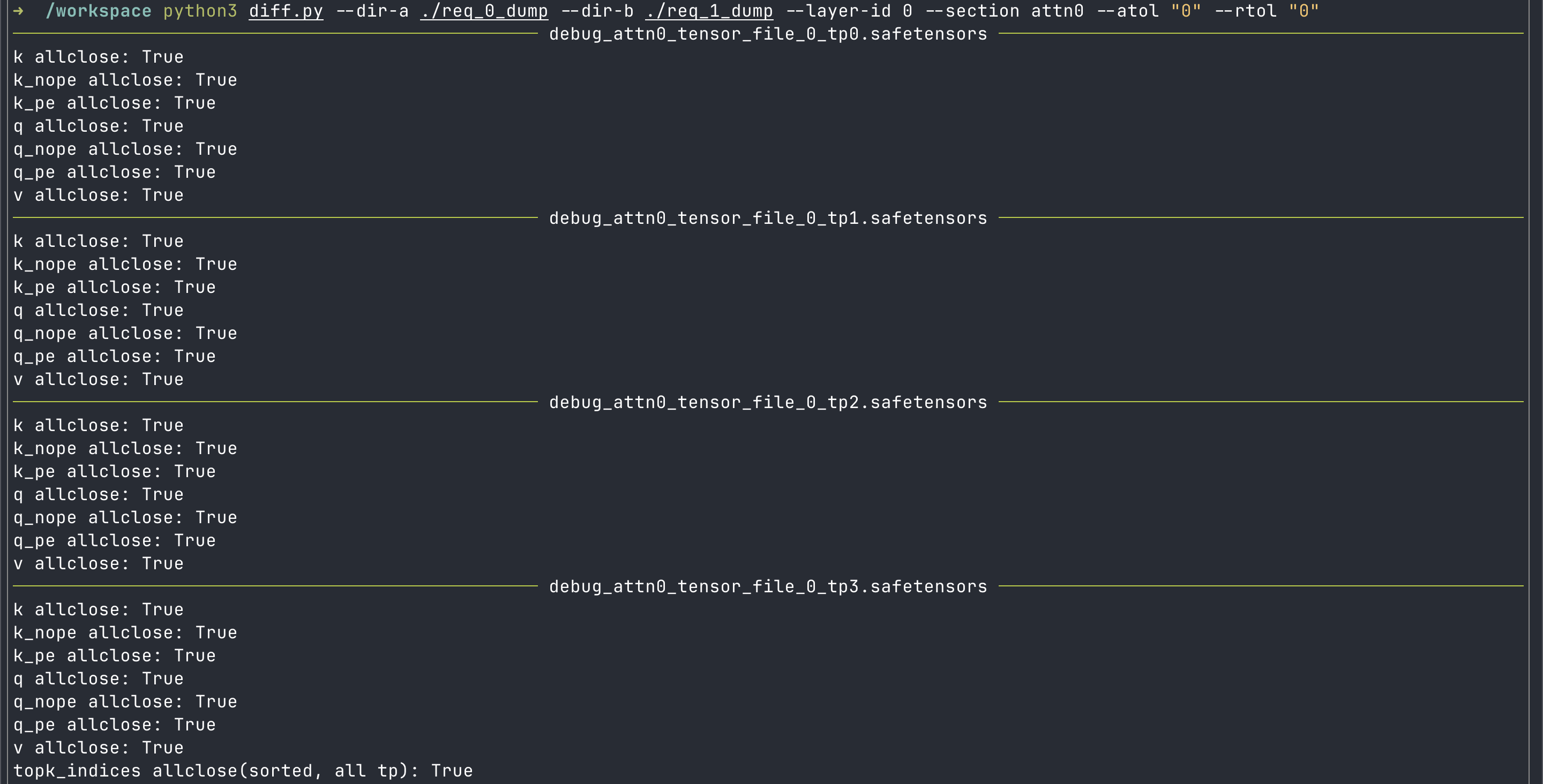
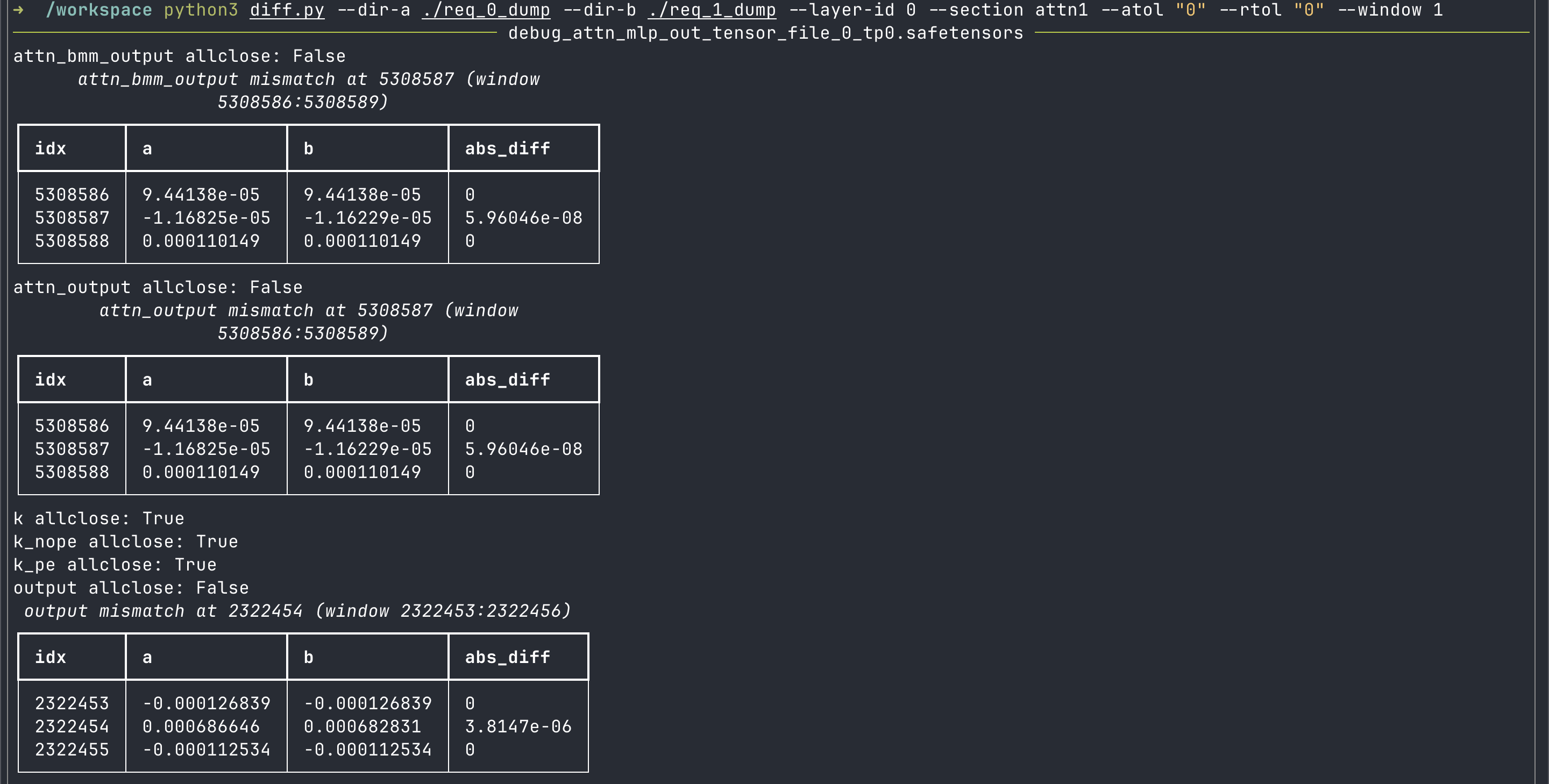
可以看到,对比结果显示attn1 的计算部分中,主要的不一样有三点:attn_bmm_output,attn_output, 以及最后的 output 不一致。而我们已知:attn1 计算部分中,最开始的计算就是flashMLA 的 Sparse Attntion,它的输出不一致,显然会造成后续所有算子输出的不一致。
因此接着我们继续追溯 Sparse Attention 的输入,输入路径包含 QKV、kvcache 以及 index,其中 QKV 经过逐项对比保持一致,因此问题不在 QKV,kvcache 需要通过 pagetable_1 索引取得,我们将 pagetable_1 排序后再按排序后的索引去取 kvcache,结果可以完全对齐,这说明 kvcache 内容一致但顺序不同,问题进一步收敛到 index 的差异。为了排除索引顺序差异只是表象这一可能性,我们对 pagetable_1 的索引集合进行严格比较,并验证排序后 kv_cache_by_pagetable 一致,从而确定差异来自 index 顺序而非索引集合,这一步把问题从写入路径排除后稳定落在索引顺序上。

最后一步是最小复现,我们使用 test_attn_mqa_determinism.py脚本 (具体代码见附录),保持 topk 集合不变,仅交换 index 顺序并在多个 GPU 上重复运行,结果稳定出现 BF16 量级差异,这说明 index 顺序变化足以引发 Sparse_Attention 输出差异,进而导致 attn1 输出不一致,以下为一次执行的 shell 输出。
run=0 device=cuda:0 same=False max_diff=0.00390625 same_bmm=False max_diff_bmm=0.0625
run=1 device=cuda:0 same=False max_diff=0.00390625 same_bmm=False max_diff_bmm=0.09375
run=2 device=cuda:0 same=False max_diff=0.00390625 same_bmm=False max_diff_bmm=0.125
run=3 device=cuda:0 same=False max_diff=0.00390625 same_bmm=False max_diff_bmm=0.0625
run=4 device=cuda:0 same=False max_diff=0.00390625 same_bmm=False max_diff_bmm=0.0625
run=5 device=cuda:0 same=False max_diff=0.00390625 same_bmm=False max_diff_bmm=0.09375
run=6 device=cuda:0 same=False max_diff=0.00390625 same_bmm=False max_diff_bmm=0.0625
run=7 device=cuda:0 same=False max_diff=0.00390625 same_bmm=False max_diff_bmm=0.0625
修改topk结果,输出后排序
很自然地,我们已知 topk 输出的时候,index 其实是无序的;那么我们会做这么一个实验,若将 topk 的输出做一次排序,岂不是可以做到两次同样的请求下,输出能一致?也可以作证前文的初步结论。于是我们可以在送入 attn 前,对 topk_indices 使用 torch.sort(stable=True)进行排序。然而,实验结果显示,在 layer7 的时候,topk 的结果发生了变化,两次 req 产生的 topk 结果并不一致!
TP Rank 1: debug_indexer_topk_tensor_file_7_tp1.safetensors
─────────────────────────────────────────────────────────────────────────
[Basic Checks]
logits_valid allclose : True
ref_sorted equal(sorted) : True
row_lens allclose : True
row_starts allclose : True
topk_result equal(sorted) : False
>> topk_result mismatch at 654597 (window 654596:654599)
┏━━━━━━━━┳━━━━━━┳━━━━━━┳━━━━━━━━━━┓
┃ idx ┃ a ┃ b ┃ abs_diff ┃
┡━━━━━━━━╇━━━━━━╇━━━━━━╇━━━━━━━━━━┩
│ 654596 │ 1665 │ 1665 │ 0 │
│ 654597 │ 1666 │ 1667 │ 1 │
│ 654598 │ 1667 │ 1668 │ 1 │
└────────┴──────┴──────┴──────────┘
topk_sorted equal(sorted) : False
>> topk_sorted mismatch at 654597 (window 654596:654599)
┏━━━━━━━━┳━━━━━━┳━━━━━━┳━━━━━━━━━━┓
┃ idx ┃ a ┃ b ┃ abs_diff ┃
┡━━━━━━━━╇━━━━━━╇━━━━━━╇━━━━━━━━━━┩
│ 654596 │ 1665 │ 1665 │ 0 │
│ 654597 │ 1666 │ 1667 │ 1 │
│ 654598 │ 1667 │ 1668 │ 1 │
└────────┴──────┴──────┴──────────┘
[Shape Info]
TP1 shapes:
A: topk=(323, 2048) int32 | logits=(323, 2590) float32
B: topk=(323, 2048) int32 | logits=(323, 2590) float32
[Comparison Logic]
TP1: A vs B topk_sorted equal = False
TP1: A topk_sorted vs ref_sorted equal = True
TP1: B topk_sorted vs ref_sorted equal = False
TP1: A vs B topk_indices equal(sorted) = False
>> TP1_A_vs_B_topk_sorted mismatch at 654597 (window 654596:654599)
┏━━━━━━━━┳━━━━━━┳━━━━━━┳━━━━━━━━━━┓
┃ idx ┃ a ┃ b ┃ abs_diff ┃
┡━━━━━━━━╇━━━━━━╇━━━━━━╇━━━━━━━━━━┩
│ 654596 │ 1665 │ 1665 │ 0 │
│ 654597 │ 1666 │ 1667 │ 1 │
│ 654598 │ 1667 │ 1668 │ 1 │
└────────┴──────┴──────┴──────────┘
>> TP1_A_vs_B_topk_indices mismatch at 654597 (window 654596:654599)
┏━━━━━━━━┳━━━━━━┳━━━━━━┳━━━━━━━━━━┓
┃ idx ┃ a ┃ b ┃ abs_diff ┃
┡━━━━━━━━╇━━━━━━╇━━━━━━╇━━━━━━━━━━┩
│ 654596 │ 1665 │ 1665 │ 0 │
│ 654597 │ 1666 │ 1667 │ 1 │
│ 654598 │ 1667 │ 1668 │ 1 │
└────────┴──────┴──────┴──────────┘
可以看出,确实是存在 A 请求的 topk 输出能和 ref 的结果匹配,但是 B 请求的 topk 的输出不能和 ref 的结果匹配,且 A 和 B 请求的 topk 的输出相差一。这就很微妙,为何这里能不一样?难道是 topk 算子计算有误吗?我们要知道,由于 topk 本身的不稳定性,如果有分数相同的两个 index,此时哪个先哪个后是完全未知的,如果这俩分数正好在 topk 输出范围的边缘,就会造成输出偏差。为此,我们需要进一步证实,是否是这个原因?
用 torch.sort 替换 topk,输出对比
承接上文,为了验证是否是 topk 的问题,我们可以直接将 topk 换掉,用 torch.sort(stable=True)的方式来选取 topk 个输出。按照这个思路,我们得到了意料之内结论,一直到第 61 层的输出时,结果仍然能保持一致。
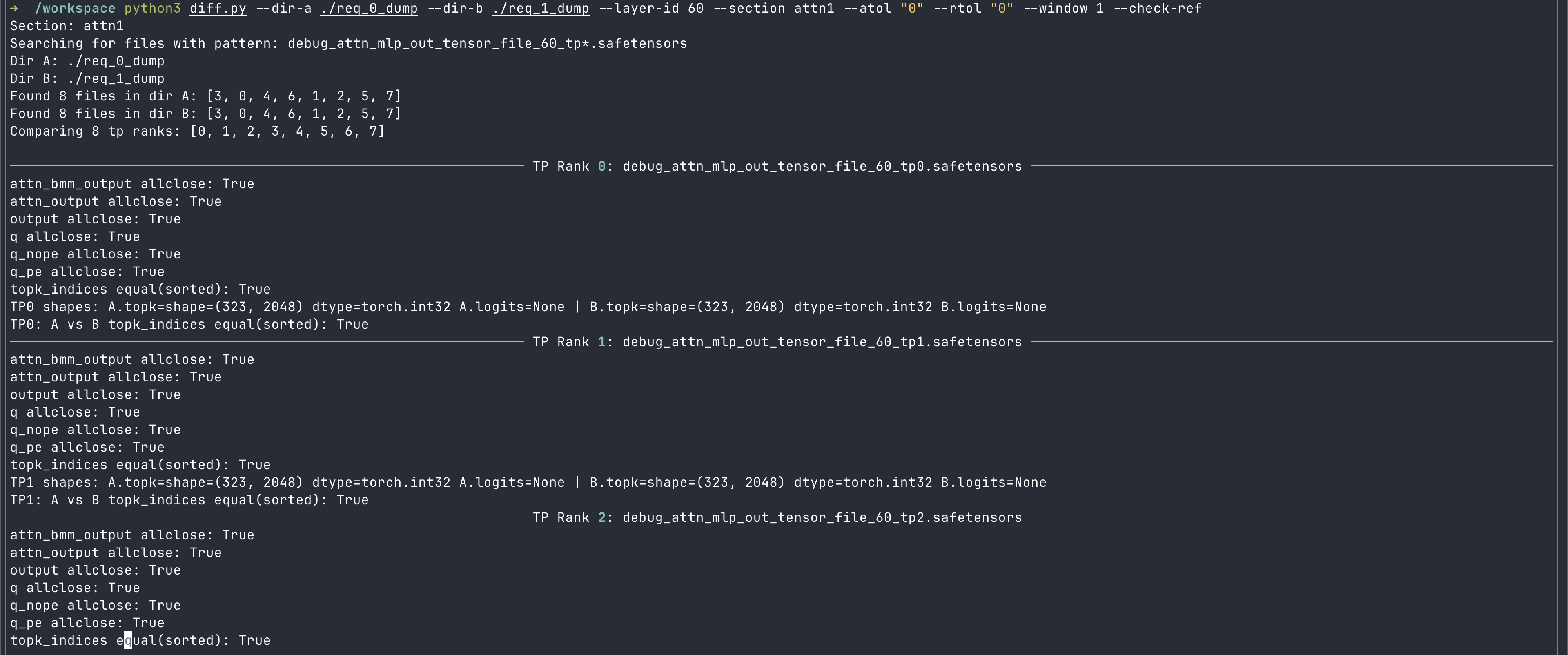 此时我们回到 layer7 去查看修改后的 topk 的输出,以及是否存在同分数的情况:
此时我们回到 layer7 去查看修改后的 topk 的输出,以及是否存在同分数的情况:
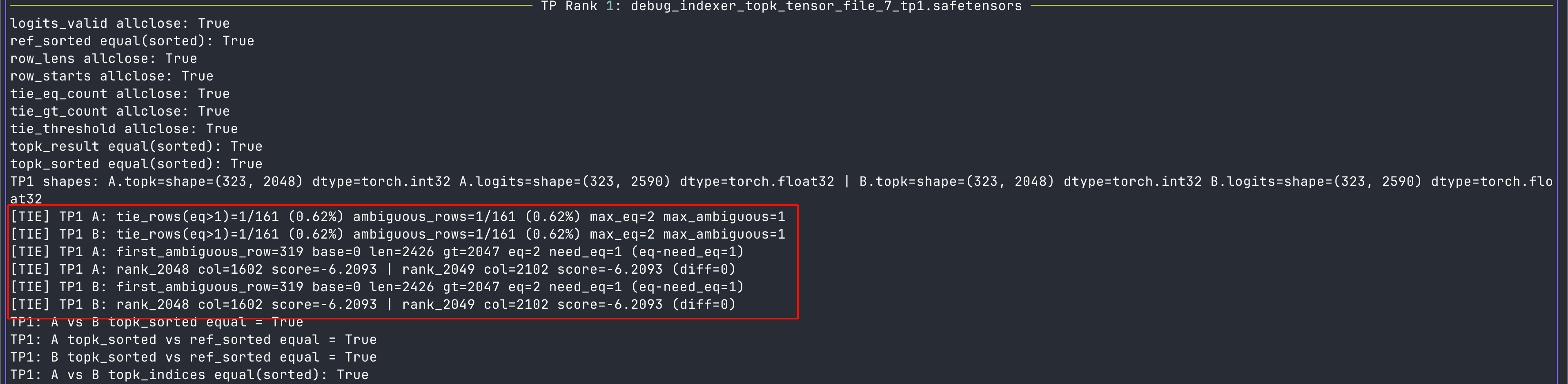 从图中可以看到,确实是存在了同分数的情况,且也正好落在 topk 的范围边缘(V32 模型选前 2048 个数),导致了如果是非稳定排序,就会导致输出的 index 相差一位。
从图中可以看到,确实是存在了同分数的情况,且也正好落在 topk 的范围边缘(V32 模型选前 2048 个数),导致了如果是非稳定排序,就会导致输出的 index 相差一位。
结论
问题的根因是稀疏化注意力输入的索引顺序不一致,虽然索引集合一致但顺序不同,导致注意力模块计算放大成输出差异,随着每经过一层的 topk 和注意力计算,误差逐步累加,最后输出的差异就如下图对比的结果一样差之千里。因此我们得出结论:对于 DeepSeek-V32 这类使用稀疏化注意力的模型,其面对相同的输入,输出本身就会存在差异,且随着层数的增多,逐步形成肉眼可观测到的差异。不仅如此,topk 的不稳定排序同样会导致其自身输出在面对同分数,且索引在输出范围边缘时,输出就会存在波动:表现为输出的 index 相差一位,且结果会进一步“污染” 后续的所有计算,从而导致哪怕是相同的请求,中途的 kvcache 也会逐渐不一致。
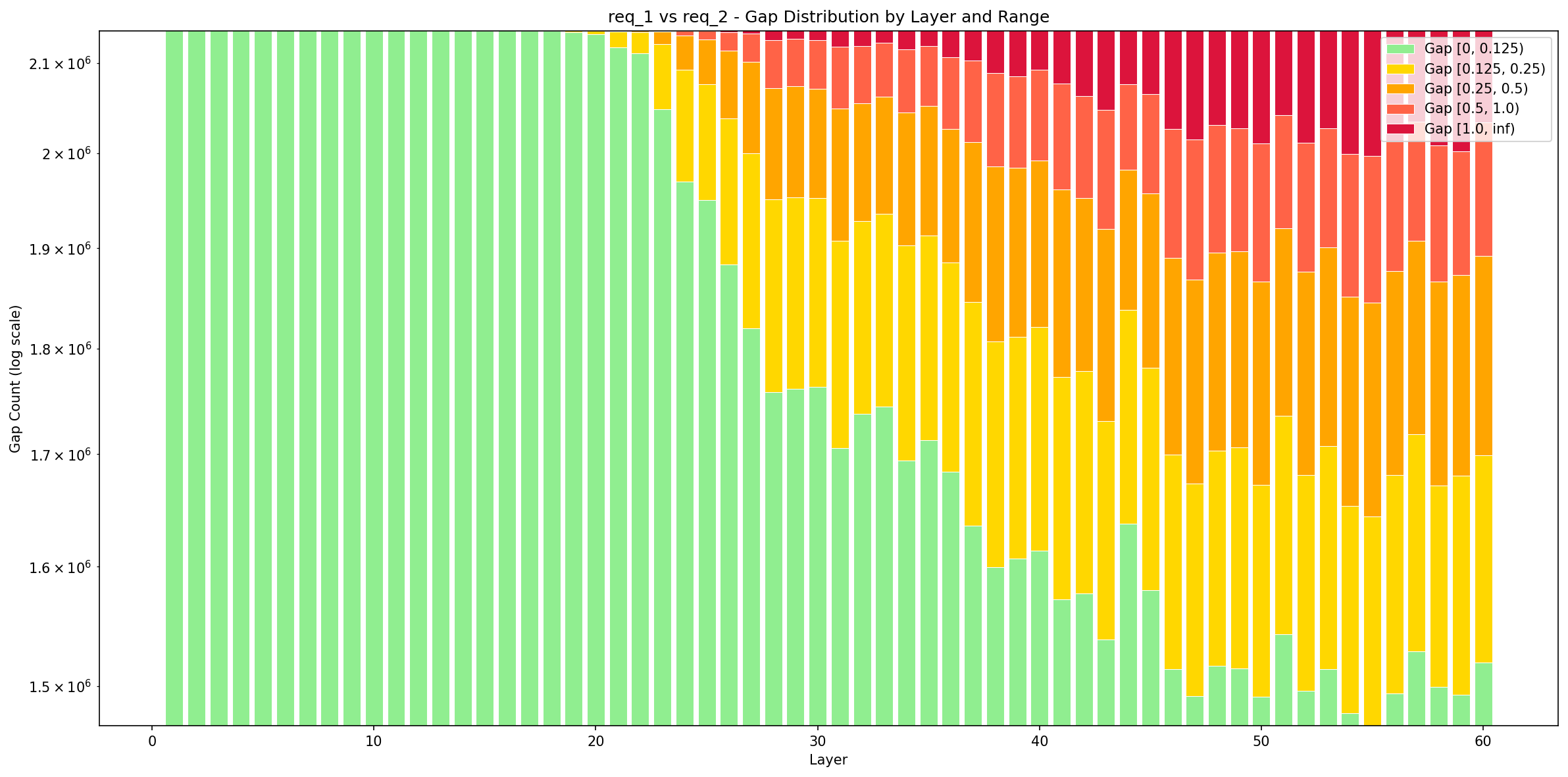
进一步探索
这一步可以把原因拆成两层,第一层是 topk 的稳定性问题,topk 在 GPU 上为了吞吐通常使用分块筛选与并行归约,尤其在 score 相等或近似相等时无法保证稳定排序,索引集合是一致的但顺序可能改变,这是性能优先带来的可接受不确定性。
第二层是 attn 的数值确定性问题,softmax 的稳定形式是先取最大值再归一化,但是在 GPU 上进行加速计算时,会选取online-softmax , 在合并两个块的结果时,会用到如下的合并公式 :
$$
\text{m}=\max(m_A, m_B)) \tag{1}
$$
$$
\text{s}= (exp(m_A-m) \cdot s_A+ \exp(m_B-m) \cdot s_B) \tag{2}
$$
有限精度下加法非结合导致不同块顺序出现不同舍入轨迹,所以顺序变化会改变最终输出,这属于数学算法在有限精度下的数值特性而非功能缺陷。具体到这次的 index 顺序变化,会导致每次计算 online-softmax 时,每次合并的这一步算法,更新的 s 的值不一致,导致了在 BF16 上的精度差异。
附录
下面给出复现与对比用到的脚本,便于完整复现和验证。