算子测试经验
1. 引言
测试算子?这不是很简单么?我一开始也是这么想的。但是实际大规模地测试后,才发现有很多坑点,比如下面的 10 问:
- 硬件是否可靠?卡有没有降频?
- 你的循环测试kernel 接口时,有没有考虑到撞到功耗墙导致降频?
- 有没有考虑到监控温度,避免撞功耗墙?
- 有没有测试卡之前先摸底,探一下卡的实际的算力/带宽峰值?
- 计时手段是在 CPU 侧计时,还是在 GPU 侧用 events?
- 计时过程是一个 for 循环,不断地 launch kernel 最后求平均值,还是使用CUDA Graph 捕图后 replay 来估算时间?
- 有没有考虑刷新 L2 的缓存?
- 输入是模拟真实场景,数据间有空间相关性,还是输入完全打乱,导致 cache miss?
- 测试出来的时间数据,进行后加工计算 MFU/MBU 时,你的 FLOPs 和 IOs 计算公式是否对齐业界?
- 测试出来的时间数据,是取平均值还是中位数?还是两者结合考虑,相差不大时采用平均数,相差较大时采用中位数?
- GEMM 算子,deep_gemm 是调用 1d1d,还是 1d2d?
- gemm 算子,一次 fp8 gemm 包含了 scale 转换的前置步骤,这段时间算不算进 kernel 时间?如果用 cuda graph 捕获后重放来计时,虽然稳定了,但是仍然会导致一些 overhead,从而和 nsys 对不上,有没有更高级的方法?
以上任意一个点没有做好,都会导致你测试出来的算子的性能和别人实际使用中的性能对不上。会怀疑你的基础架构没有做好,严重点会怀疑测试方式等等。所以下面的部分,会从算子自己的性能优化入手,先了解算子是怎么 work 的,才能有的放矢地对算子性能做系统性地评估。
2. 以 Attention 算子为例
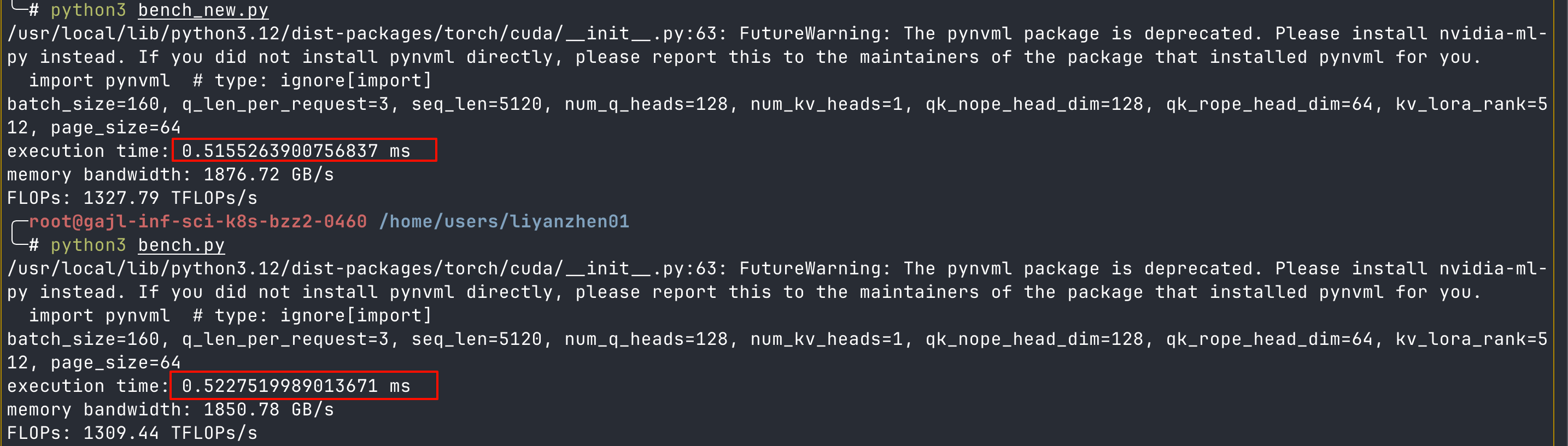
真实 case:在部署的引擎中,bs=160,q_len=3, kv_len=5003+200 约等于 5k 时,nsys 抓取出来的图表中显示,kernel 的耗时为 430 us。 使用测试框架/脚本进行算子单测时,最终时间耗时为 501 us 左右。这中间存在许多 gap,需要逐一排查。
2.1 测试框架撞到功耗墙:误差 60us
这个 bug 隐藏的比较深层,原因是:cuda graph 的重放时间够长,重放多次时,中间没有缓冲时间,导致 GPU 功耗满载超过 100ms,导致主频降低。从 1.9GHZ 降频到 1.2GHZ。如下图所示:
解决办法:在 replay 循环中,加入短暂地 sleep 过程,避免长时间高功耗,同时降低一个图的重放时间。
效果:采集的耗时从 588us 降低到 522us 左右。
2.2 block分配对齐引擎且关闭 l2_flush
在传统的测试中,为了测试算子的真实性能,往往都是去掉时空局部性,即强迫算子 cache miss,从而暴露真实耗时。而在引擎部署服务时,block 是按顺序分配的,如下面的部分代码所示:
block_tables = torch.full(
(bs, max_num_blocks_per_seq),
-1,
dtype=torch.int32,
device=device_t,
)
cur_block = 0
for i in range(bs):
n = int(blocks_per_seq[i].item())
if n == 0:
continue
block_ids = torch.arange(cur_block, cur_block + n, dtype=torch.int32, device=device_t)
block_tables[i, :n] = block_ids
cur_block += n
# Generate random but unique block IDs for all sequences
total_blocks_needed = sum(blocks_per_seq)
all_block_ids = torch.randperm(
total_blocks_needed, device=device
) # Random permutation
# Generate unique block IDs for all sequences
block_id = 0
block_tables = torch.zeros(
(batch_size, max_num_blocks_per_seq), dtype=torch.int, device=device
)
# Populate block tables and track block assignments
block_id = 0
for i in range(batch_size):
num_blocks_needed = blocks_per_seq[i]
block_tables[i, :num_blocks_needed] = all_block_ids[
block_id : block_id + num_blocks_needed
]
block_id += num_blocks_needed
这两种不同的分配方式,带来了不同的性能表现,如下图所示:
效果:误差降低7us
2.3 独占测试机器
后续在独占 8 卡机器后,得出目前的shape 的性能:
python3 -m aiak_ds_tool.search \
--device b200 \
--op mla \
--backend flashinfer \
--version 0.5.3 \
--dtype bf16 \
--q_length 3 --kv_length 5120 --batch_size 160
filters: params={'batch_size': 160, 'q_length': 3, 'kv_length': 5120}
[LIST] op=mla backend=flashinfer version=0.5.3
info: Listed 1 matched rows
matched rows: 1
{ tp_size=1, batch_size=160, q_length=3, kv_length=5120, time(us)=501.9, MFU=0.5455, MBU=0.2527 }
source: db:/Users/liyanzhen/Documents/baidu/PUBLIC/aiak_ds_tool/aiak_ds_tool/data/b200.db:mla_c16_flashinfer_0.5.3
- 需要进一步探索为啥有这个 diff