闪电模型 nsys-profiler
1. 结论
1.1 目标 & 状态
目标:为了适配上 BZZ2 上,根据需求方给出的验收要求进行反向计算,得出如下的吞吐要求:
D 节点要求
| 单机吞吐 | OTPS | TPOT | DP Size | BS per DP | 接受率 | 前向时间 | |
|---|---|---|---|---|---|---|---|
| 用户&引擎视角 | 用户视角 | 用户视角 | 引擎视角 | 引擎视角 | 引擎视角 | 引擎视角 | |
| 目标 | 11520 | 11520 / 24 / 8 = 60 | 1000 / 60 = 16.6 ms | 8 | 24 | 2.3 | 2.3 * 1s / OTPS = 38.33 ms |
| nsys 反算 | 15496 | 80.71 | 12.39 ms | 8 | 24 | 2.3 | 28.5 ms |
P 节点要求
| 单机吞吐 | TTFT | DP Size | BS per DP | 接受率 | 前向时间 |
| 用户& 引擎视角 | 用户视角 | 引擎视角 | 引擎视角 | 引擎视角 | 引擎视角 |
| 1 s | 8 | 2.3 |
1.2 结论
按照当前的测试规模和测试方式,目前引擎是达标的,符合预期。
从 NSYS 的报告来看:每输出
2.3个 tokens,花费时间约为28.5 ms,那么不考虑链路引入的其他耗时,此时在用户看来,一个 token 需要花费 $28.5\ / \ 2.3 = 12.39\ \text{ms}$ . 满足面表格中提到的目标:TPOT 小于16.6 ms从下文的第四小节的模拟器分析来看:当前和模拟器给出的分析报告可以互相印证,主要差异在 Attention 的算子耗时,其余算子耗时均能对应。而这个耗时不同是由于数据集并不是 4K 输入长度的均衡数据集,而是存在长尾输入的非均衡数据集。
2. 实验设计
2.1 实验设计说明
| 目的 | 实际行为 |
|---|---|
| 验证是否达标 | 采集 BZZ2 上的实际数据集下的表现 |
2.2 具体参数
| 模型 | 机器 | 数据集 | bs / DP |
|---|---|---|---|
| L1.1 | BZZ2 | 24 |
3. Decode 阶段算子详细分析
3.1 结论
可能的待优化点:
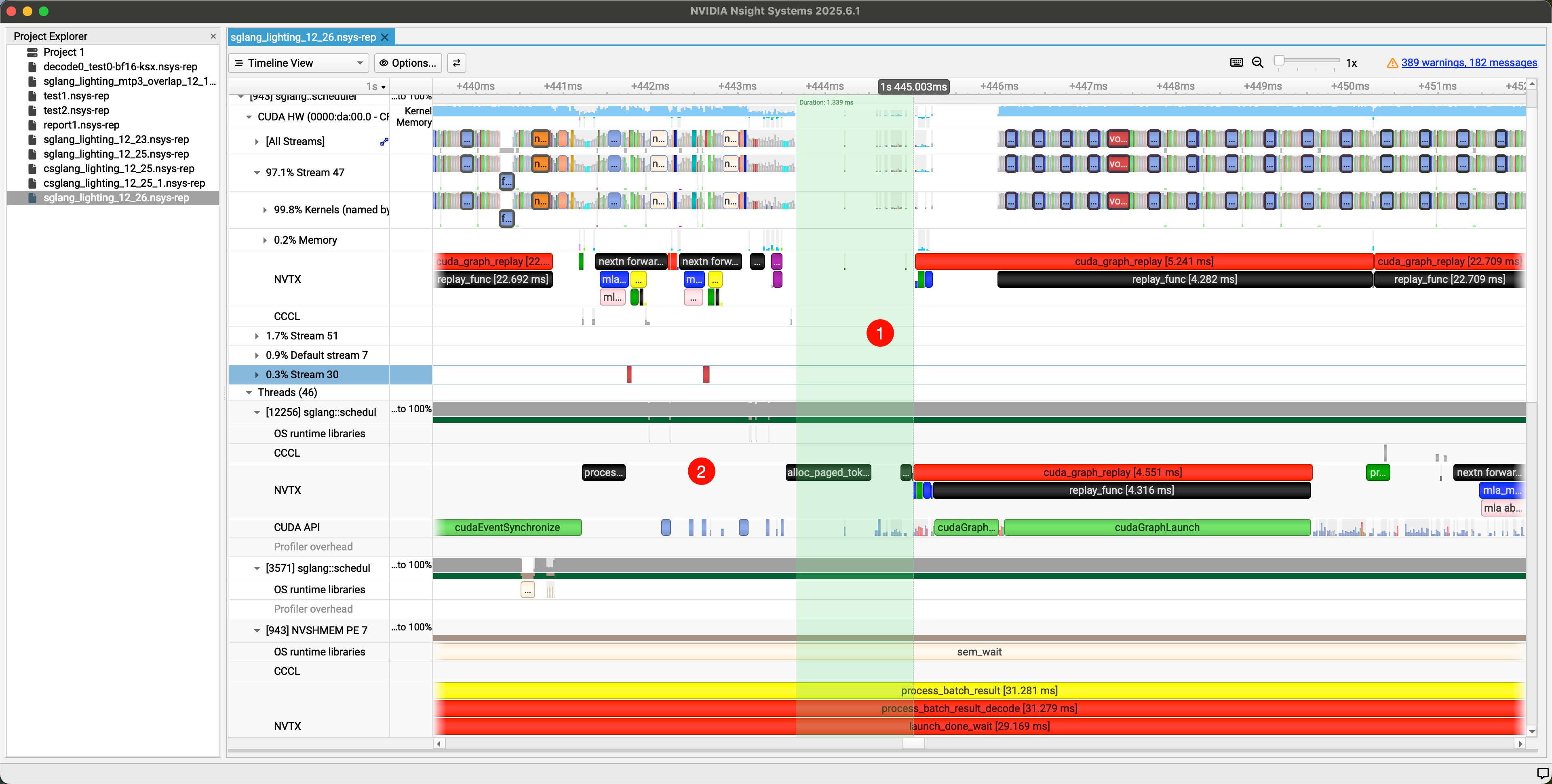
两次 forward 间隙较大,nsys 中查看,可以看到是1.3ms。且多卡均有该问题。
3.2 单算子拆分
| 算子名拆分 | nsys 具体执行时间 | |
|---|---|---|
| atten 耗时 (1~3 层) | — | — |
| RMS Norm | 8 us | |
| q_a_kv_a | 11 us | |
| RMS_Norm_Split_Col | 4 us | |
| q_proj_b | 2 + 14 = 16 us | |
| bmm | 8 + 2 = 10 us | |
| rope | 7 + 2 + 5 = 15 us | |
| atten | 153 us | |
| bmm | 6 + 5 = 11 us | |
| o_proj | 3 + 30 = 33 us | |
| Fused_Add_RMS_norm | 3 | |
| mlp 耗时 | mlp_clomn_gemm (UP) | 2+22 = 24 us |
| silu | 5 us | |
| mlp_row_gemm (Down) | 18 us | |
| 一层共计耗时 | Dense_Total | 0.311 ms |
| 三层共计耗时 | Dense_Total * 3 | 0.311 * 3 = 0.933 ms |
| atten 耗时(4~61 层) | — | — |
| Fused_Add_RMS_norm | 4 us | |
| q_a_kv_a | 11 us | |
| RMS_Split_Col | 4 us | |
| q_proj_b | 2 + 14 = 16 us (+per_token_quant) | |
| bmm | 7 + 3 = 10 us (+ elementwise) | |
| rope | 7 + 2 + 5 = 14 us (+ elementwise) | |
| atten | 150 us | |
| bmm | 6 + 4 = 10us | |
| o_proj | 3 + 29 = 32 us | |
| Fused_Add_RMS_Norm | 3 us | |
| 路由层 | gate+topk | 19 us |
| share 专家 | up_gemm | 3 + 12 = 15 us |
| silu | 2 us | |
| down_gemm | 6 us | |
| MoE 层 | dispatch | 43 us (未掩盖部分) |
| up_gemm | 40 us | |
| silu | 2 + 4 = 6 us | |
| down_gemm | 30 us | |
| combine | 12 us (未掩盖部分) | |
| 后处理 | combine + element | 8 + 2 + 2 = 12 us |
| 一层耗时 | MoE_Total | 0.439 ms |
| 58 层耗时 | MoE_Total * 58 | 25.46 ms |
| 投机解码耗时 | MTP_Total | 2 ms |
| 3 个 token 的生成耗时 (考虑到 MTP 实际接受率,为2.3个 token | Dense_Total * 3 + MoE_Total * 58 + MTP_Total | 28.5 ms |
4. 模拟器模拟
4.1 结论
真实场景和模拟器给出的性能分析能对应上(不是直接吞吐/前向时间对齐),GEMM,通信等算子基本能对应,diff 较小;主要差异点存在于 Attention 算子的耗时。结论是压测数据集的不均衡性,带来的Attention 耗时的不同。
因此,如果维持部署规模/参数,压测的并行数,不均衡数据集保持不变的前提下,当前的一次 Forward 耗时接近理想情况。
更进一步,如果保证 OTPS 大于 60 的验收结果,当前 D 节点可以接收更大的并行数的压力测试。
4.2 模拟器结果
[!important]
注意:模拟器模拟的是上下文 4K,绝对均衡的理想场景下的表现。仅提供指导意见,不完全匹配得上真实场景。
python3 -m aiak_infer_tools simulator --model lightning --mode batch
得出如下图所示的模拟结果:
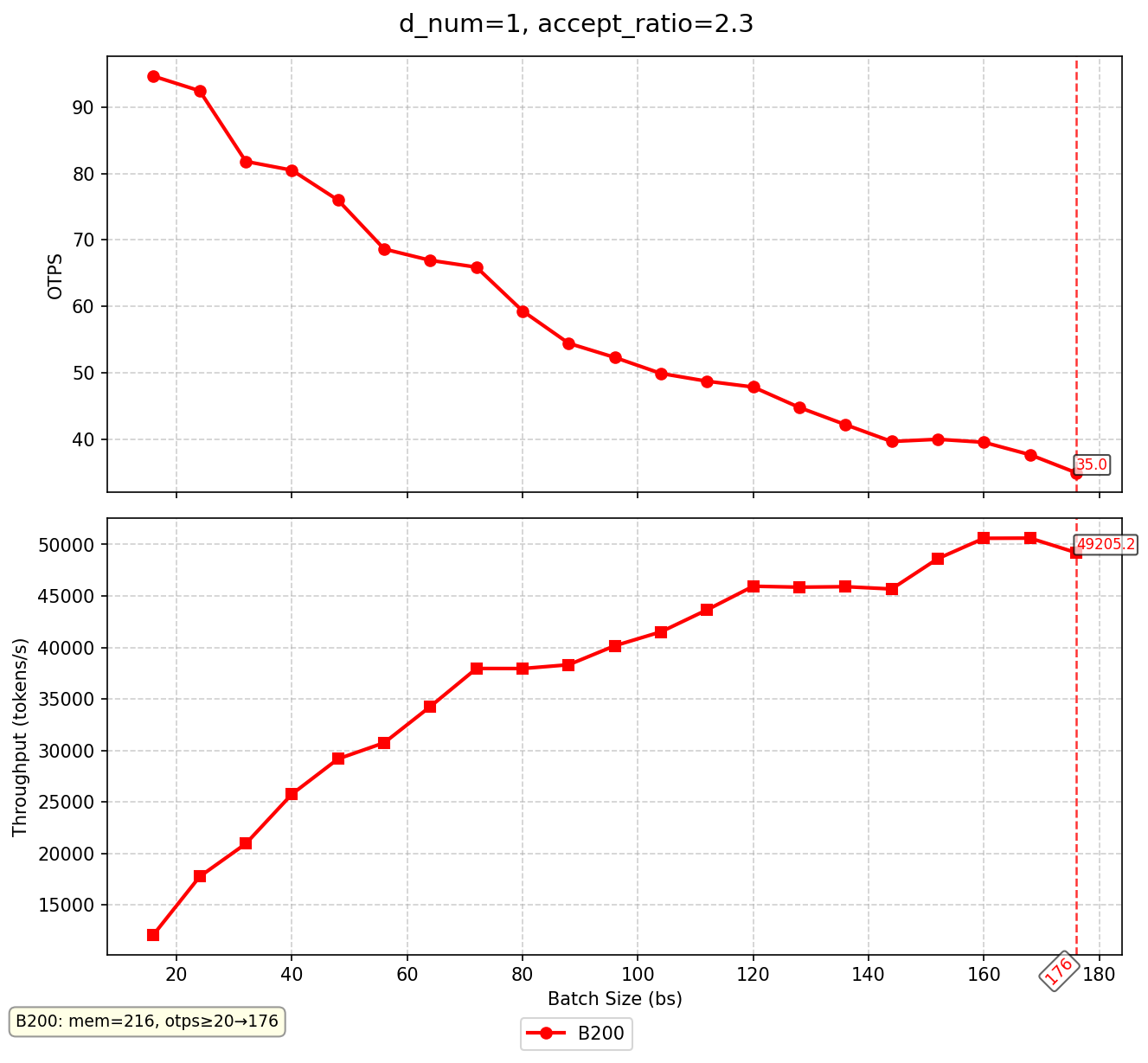
可以看到,在满足客户需求 $\text{OTPS} \gt 60$ 的情况下,理想情况下,单一 D 节点可以接收的并行处理数目为72. 另一个结论是,在当前测试场景下 (bs =24)时,OTPS 极限可以到达 92. 远比实际测试的结果来的高。下面会具体对比 模拟—真实 之间的差异。
4.3 diff 分析
| op_name | time(us) | OP_DIFF (us) | Total_DIFF_vs_nsys (ms) |
| mla | 63.82 | - 86 us | - 86 * 61 = - 5.3 ms |
| moe_up_gate_proj | 41.18 | + 1 us | + 1 * 58 = + 0.058 ms |
| moe_down_proj | 32.05 | + 2 us | + 2 * 58 = + 0.116 ms |
| o | 31.28 | 0 | 0 |
| low_latency_combine | 31.07 | + 18 us | + 18 * 58 = + 1.04 ms |
| low_latency_dispatch | 30.21 | - 13 us | - 13 * 58 = - 0.75 ms |
| mlp_down | 20.36 | + 2 us | + 2 * 3 = + 0.006 ms |
| mlp_up_gate | 19.51 | - 4 us | - 4 * 3 = - 0.012 ms |
| q_b | 14.34 | -2 us | - 2 * 61 = - 0.122 ms |
| share_up_gate | 13.90 | - 1 us | - 1 * 58 = - 0.058 ms |
| q_a_kv_a | 13.87 | + 3 us | + 3 * 58 = 0.174 ms |
| gate + TopK | 19 | 0 | 0 |
| share_down | 6.92 | + 1 us | + 1 * 58 = + 0.058 ms |
| Total | 24.88 ms | — | - 4.68 ms |
可以看到,在加上这些 diff 后,一次前向时间来到 **29 ms, 接近 nsys 真实数据。**最大差异点是 Attention 算子的计算时长不同。合理怀疑是压测数据集的不均衡导致的性能问题。
5. 进一步实验
针对上文中提到的,怀疑是压测数据的请求长短不平衡,存在长尾,导致抓取 nsys 时的 Attention 耗时增加这个观点,进一步做一下实锤工作 — 把数据集输入控制在 4K 左右,再抓取一次 nsys,查看报告。
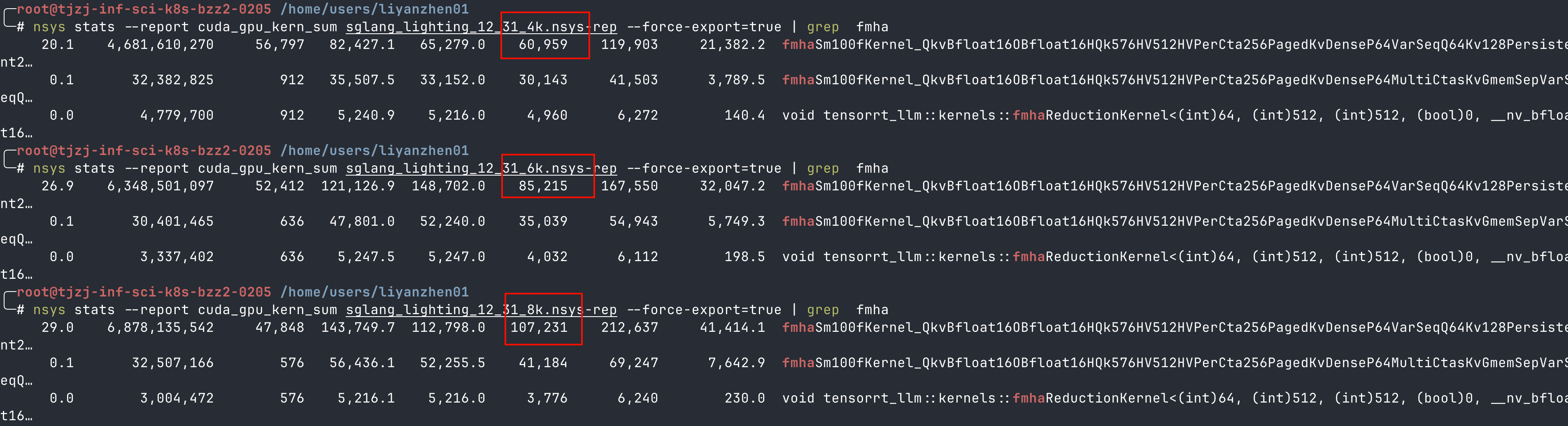
分别抓取了 4k,6k,8k 的定长输入下的nsys,只分析 fmha 这个算子,可以看出,4k 到 6k 的耗时,基本等于 1.5 倍;6k 到 8k 的耗时,基本等于1.3 倍。符合单算子的耗时比例。