DS-V4 分析&学习
DS-V4 分析&学习
0. 摘要
首先给出一图流进行学习,重点都突出在下面了。
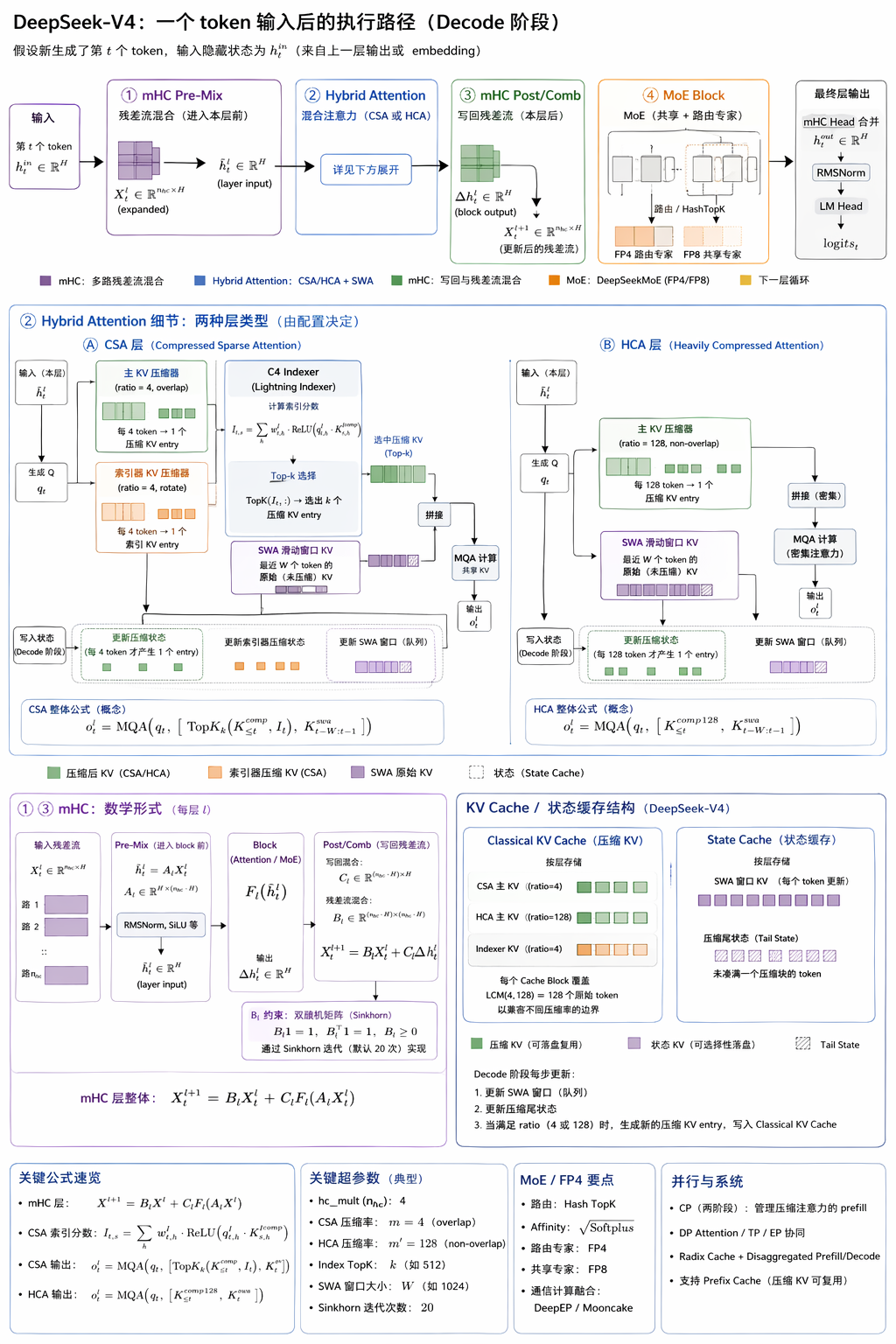
DeepSeek-V4 的核心变化不是单纯扩大模型,而是重新设计 1M 级上下文下的 Attention 与 KV Cache 成本模型:
- CSA = compression + sparse top-k + SWA
- HCA = heavy compression + dense compressed attention + SWA
- KV cache = compressed cache + state cache + SWA cache + tail state
1. 理论重点:Attention 的变化
DeepSeek-V4 的 Attention 不再让每个 query token 直接 attend 到所有历史 token,而是先把历史 token 压缩成更少的 KV entry,再根据层类型选择“稀疏看一部分”或者“密集看压缩后的全部”。论文里把这个叫做 Hybrid Attention with CSA and HCA:
- CSA:Compressed Sparse Attention。每
m个 token 压成 1 个 compressed KV entry,然后通过 indexer 选 top-k 个 compressed entry 做 attention。 - HCA:Heavily Compressed Attention。每
m'个 token 压成 1 个 compressed KV entry,m' >> m,但压缩后不做 sparse top-k,而是 dense attention over compressed KV。
1.1 普通 Attention 的瓶颈
普通 self-attention 在 decode 阶段虽然每次只生成一个 token,但这个 token 仍要和所有历史 KV 做 dot product:
q_t = h_t @ Wq
score_t = q_t @ K_cache.T
out_t = torch.softmax(score_t, dim=-1) @ V_cache
当 past_len = 1M 时,这不只是算力问题,还有显存问题。
1.2 CSA:先压缩,再稀疏选择
Token-level KV
-> 每 m 个 token 压成 1 个 compressed KV
-> Lightning Indexer 给 compressed KV 打分
-> 选 top-k
-> query 只 attend 到这 k 个 compressed KV + sliding window KV
CSA 类似数据库里的“先用粗索引找候选行,再对候选行做精确计算”。它和 kv_offload 迁移至社区 HiCache 初稿、基于社区已有的部分 PR 实现 offload 里关注的 sparse KV 工作集管理直接相关。
1.3 CSA 的 overlap compression
CSA 不是简单每 m 个 token 切块独立压缩。一个 compressed entry 实际会看相邻的 2m 个位置,前后 block 有 overlap。这样 block 边界更平滑,但 decode 时 cache state 维护更复杂。
1.4 HCA:更激进压缩,但不稀疏
CSA: 每 4 个 token -> 1 个 compressed KV,然后 top-k sparse attention
HCA: 每 128 个 token -> 1 个 compressed KV,然后 dense attention over compressed KV
如果原始上下文是 1M token,HCA 按 128 压缩后只剩约 8192 个 compressed KV entry。
1.5 Sliding Window Attention
CSA/HCA 负责远处信息,SWA 保留最近 token 的精确信息。远处信息用概要,近处信息保留原文细节。
2. 工程重点:KV Cache 的变化
DeepSeek-V4 不是运行时自由选择 CSA 或 HCA。CSA/HCA 写在模型 config 中,每层固定使用一种 attention。
compress_ratio = config.compress_ratios[layer_id]
if compress_ratio == 0:
attn = SlidingWindowAttention(...)
elif compress_ratio == 4:
attn = CSAAttention(...)
elif compress_ratio == 128:
attn = HCAAttention(...)
单层只消费一种 cache 形态;全模型层间混合多种 attention cache 形态,所以 runtime 必须同时支持 c4 / c128 / SWA / state。
3. 训练重点:mHC 的引入
mHC 是多路 residual stream。它不是 V4 长上下文效率的主因,更像模型能力和训练稳定性的结构增强。相关实现学习可以接到 mHC 算法分析 & cutile 高效实现。
4. 工程 Trick
- MoE 专家权重引入 FP4,降低专家权重显存压力。
- CSA indexer 的 QK path 也要低精度,否则 indexer 会变成热点。
- MoE 通信计算融合,把专家分 waves,某一波 token 到了就先算。
- TileLang / fused kernel 用来减少 mHC、compressor、top-k transform、quant/dequant 等小 kernel launch。
- MTP / NextN 支持必须对齐 V4 的 mHC hidden shape、DeepSeekV4 KV pool 和 speculative worker。
- Batch-invariant / deterministic kernel 对训练和排障很重要。
参考
- DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
- MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
- SpAtten / Longformer / BigBird
- Multi-Query Attention / Grouped-Query Attention