GroupGEMM 最佳效率探索
符号与记号约定
| 符号 | 含义 | 取值范围 / 单位 | 备注 |
|---|---|---|---|
| $B$ | Batch size(当前解码轮参与的请求数) | 正整数 | 原义是指 Global BS;这里指每个 DP 实例拿到的 B |
| $Q$ | 本轮每个请求新增 token 数(q_len) | 正整数 | |
| $D$ | 数据并行(DP)实例数 | 正整数 | |
| $K$ | MoE gating 的 Top‑K | 1…$E$ | |
| $E$ | 总专家数(per 模型) | 正整数 | |
| num_groups | 本卡 GroupGEMM 中被激活专家组数 | 0…本卡专家数 | 取 $\min(\text{本卡专家数}, \text{本轮有效子批次数})$ |
| $m[i]$ | 第 $i$ 个激活专家的子 batch 大小 | 非负整数 | GroupGEMM 每组的 M 维 |
| $T_{\text{total}}$ | 本轮产生的新 token 总数 | $B\times Q$ |
0. 引言
在多节点的 Prefill‑Decode(PD)分离部署中,开启DP_MoE选项后,专家会分布到多个数据并行(Data Parallel, DP)实例上。于是每个专家拿到的 token 数量,会随这几个变量变化:批处理大小 $B$、数据并行数 $D$、单轮新增 token 数 $Q$、以及 Top‑K $K$。我们聚焦 GroupGEMM 算子,它的两个关键入参 num_groups 与 $m[i]$ 同时受上述因素影响。为了最大化解码阶段效率,需要一套“可计算、可验证”的跨层映射与经验指引。
1. 理论计算
为避免符号混杂,按三层语义展开:引擎配置层 → MoE 路由层 → GroupGEMM 算子层;随后给出跨层映射与推论。
1.1 配置层(DP/EP 等)
节点与并行:
- 数据并行数:$D = \text{dp_size}$
批处理与步长:
批处理大小:$B = \text{batch_size}$
本轮每请求新增 token 数:$Q = \text{q_len}$
单轮新 token 总数:$T_{\text{total}} = B\times Q$(见式 (1))
MoE 结构与调度:
总专家数(模型级):$E = 256$(DeepSeek‑V3)
每 token 选路 Top‑K:$K$($1 \le K \le E$)
每个 DP 实例上的本地专家数:$E_{\text{node}}$
可选多步解码:MTP(若开启,会影响 $Q$)
1.2 MoE 路由层(token → expert)
- 单 DP 节点承接的新 token 数(假设在 $D$ 上均匀切分):
$$T_{\text{node}}
= {B\times Q}\tag{1}$$
- Top‑K 路由复制使每个 token 分配到 $K$ 个专家;忽略倾斜且假设均匀或已负载均衡,则本节点本地专家合计样本数近似:
$$T_{\text{expert,node}} \approx T_{\text{node}}\cdot K
= {B\times Q\times K}\tag{2}$$
- 若考虑不均衡或容量门控,设倾斜系数 $\alpha \ge 1$,则最繁忙本地专家的子批量上界近似:
$$m_{\max} \lesssim \alpha,\frac{T_{\text{expert,node}}}{E_{\text{node}}}
= \alpha,\frac{B\times Q\times K}{E_{\text{node}}}\tag{3}$$
1.3 GroupGEMM 算子层(num_groups, m, n, k)
记本卡被激活的专家集合大小为 num_groups,记第 $i$ 个被激活专家的子批为 $m[i]$,各组 GEMM 形状:
$M_i = m[i]$
$N$ 为输出特征维,$K_\text{gemm}$ 为输入特征维
激活规则与上界:
一轮解码中,未分到样本的本地专家不激活,不计入 num_groups。
因此有:
$$\text{num_groups} \le \min\Bigl(E_{\text{node}},; T_{\text{expert,node}}\Bigr)\tag{4}$$
- 在绝对均匀路由近似下,期望每组子批量:
$$\mathbb{E}[m[i]] \approx \frac{T_{\text{expert,node}}}{E_{\text{node}}}
= \frac{B\times Q\times K}{E_{\text{node}}}\tag{5}$$
1.4 跨层映射:从 ${B,Q,D,K,E_{\text{node}}}$ 到 ${\text{num_groups}, m[i]}$
- 期望层面($\alpha=1$):
$$\boxed{;\mathbb{E}[m[i]] \approx \dfrac{B\times Q\times K \times D}{ E};}\tag{5 重述}$$
$$\boxed{;\mathbb{E}[\text{num_groups}] \approx \min!\Bigl({\frac{E}{D}},; {B\times Q\times K}\Bigr);}\tag{4 重述}$$
1.5 推论与小节(由式 (3)(4)(5))
小批量退化:在 $E_{\text{node}}$ 与 $D$ 固定时,$B$ 或 $Q$ 过小,会使 $\mathbb{E}[m[i]]$ 掉到 0/1 的离散台阶,空组与极小组增多,GroupGEMM 易退化。(见式 (5))
适度收缩 $D$:在吞吐允许时,减小 $D$ 可线性抬升 $\mathbb{E}[m[i]] \propto 1/D$,提升算子利用。(见式 (5))
调高 $K$ 的权衡:增大 Top‑K 使 $\mathbb{E}[m[i]] \propto K$,一定范围内可缓解离散退化,但带来通信与计算开销,需端到端评估。(见式 (5))
放置与路由:通过专家放置与容量门控降低 $\alpha$,可减少最坏专家抖动与尾部延迟。(结合式 (3))
2. 实际性能测试
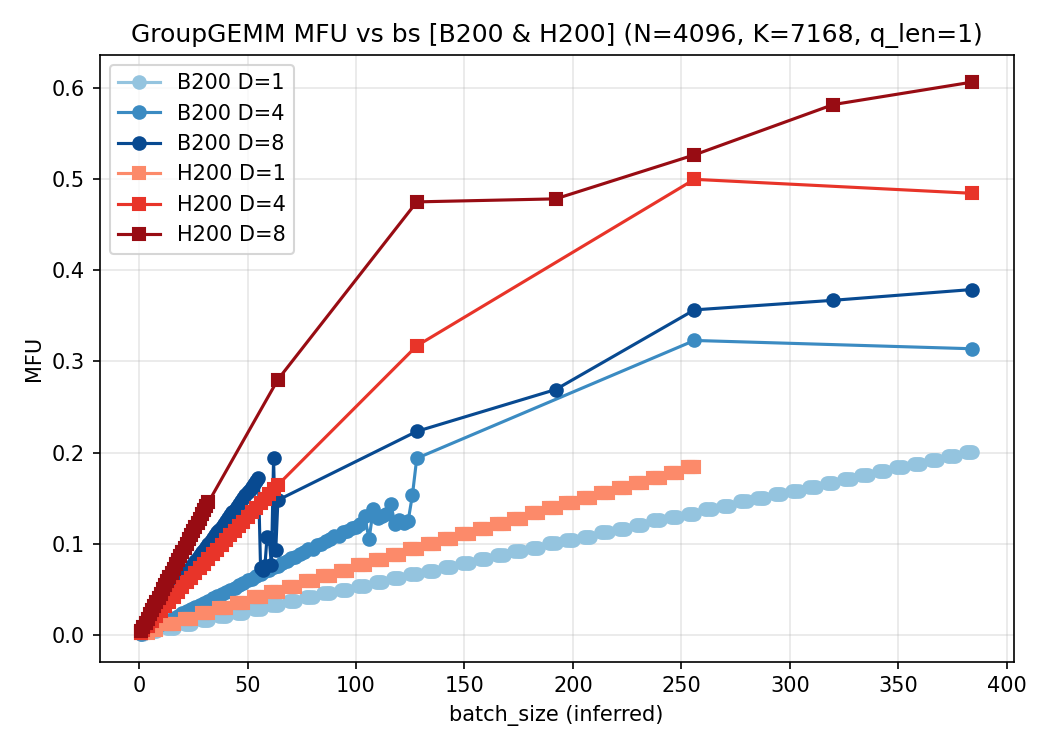
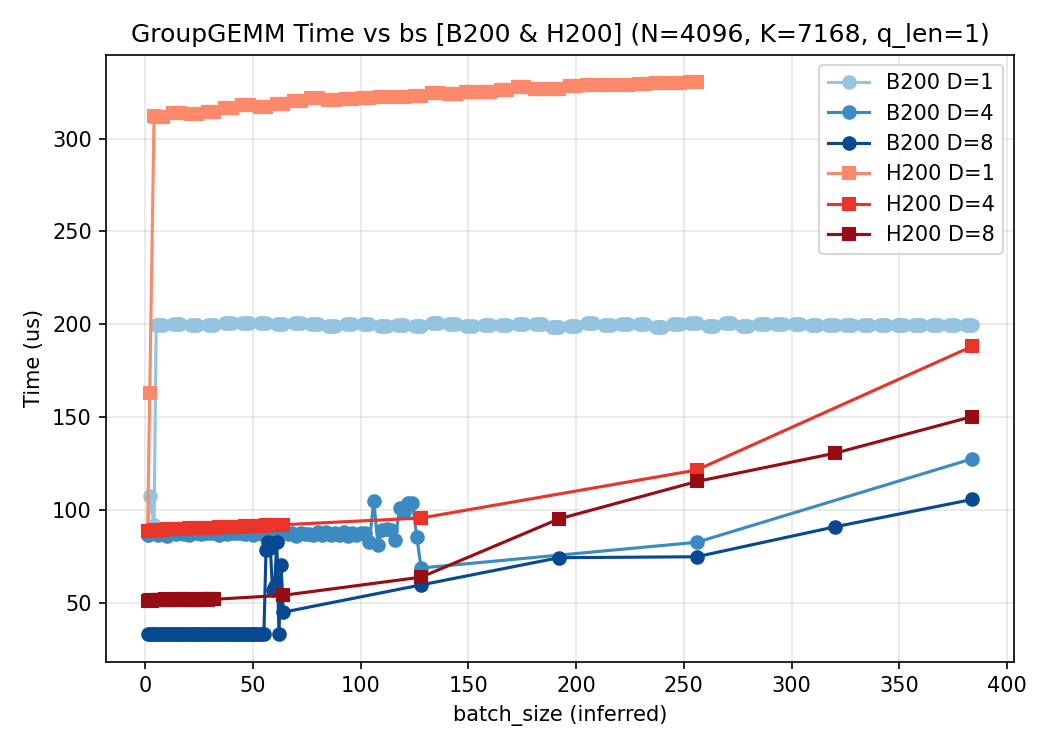
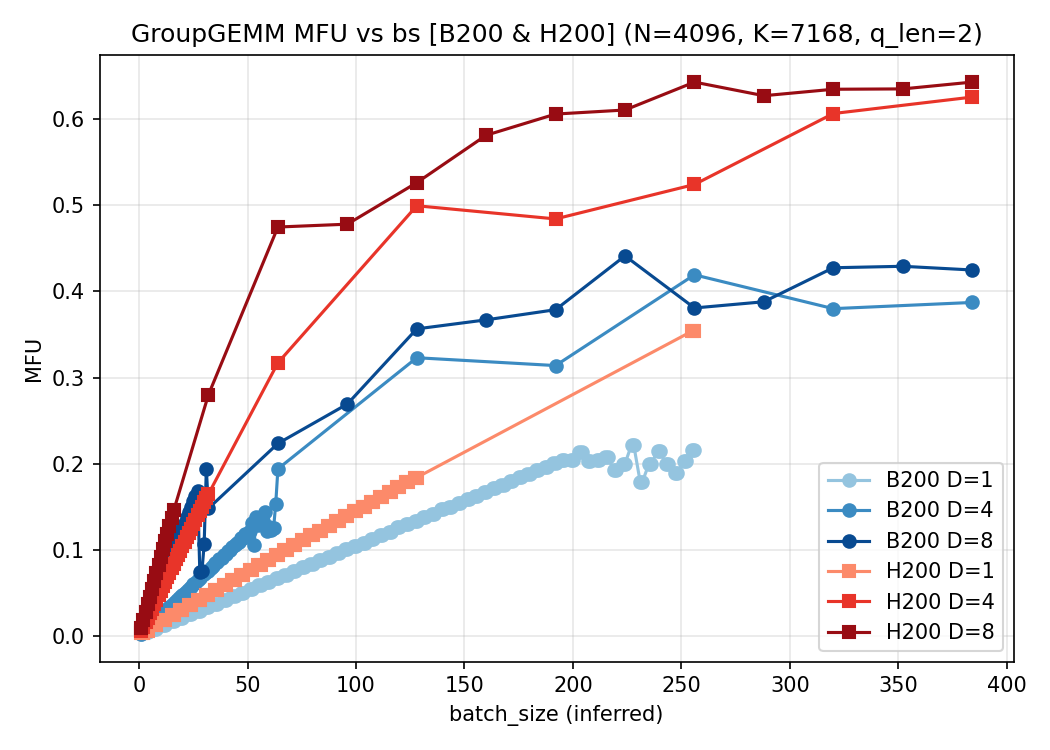
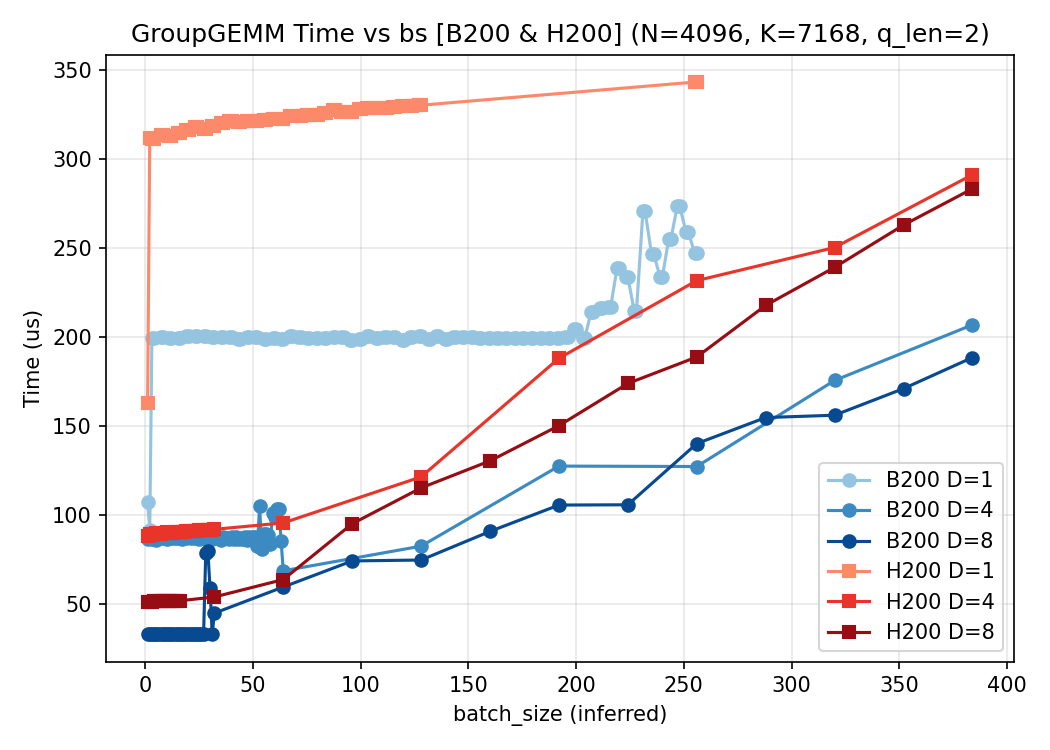
2.1 固定 $K=8,; E_{\text{node}}=256$
考虑解码节点部署 DeepSeek 系列模型,$E_{\text{node}}=256$ 且 $K=8$。在该设定下,num_groups 与 $m[i]$ 的近似关系为:
$$\text{num_groups}
= {8},\times, \min\bigl(\frac{32}{D},; B\times Q\bigr)\tag{6}$$
$$\text{m[i]}
= \Bigl\lceil,\frac{B\times Q \times D}{32},\Bigr\rceil\tag{7}$$
式 (6) 与式 (7) 可由式 (4)(5) 推出,利用 $E=256$ 与分段上界 $\min(\cdot)$ 的离散性。
下面给出 $Q\in{1,2,3,4}$ 在 H200 和 B200 上采集的数据,对比 MFU 与耗时:
$Q=1$:
$Q=2$:
$Q=3$:
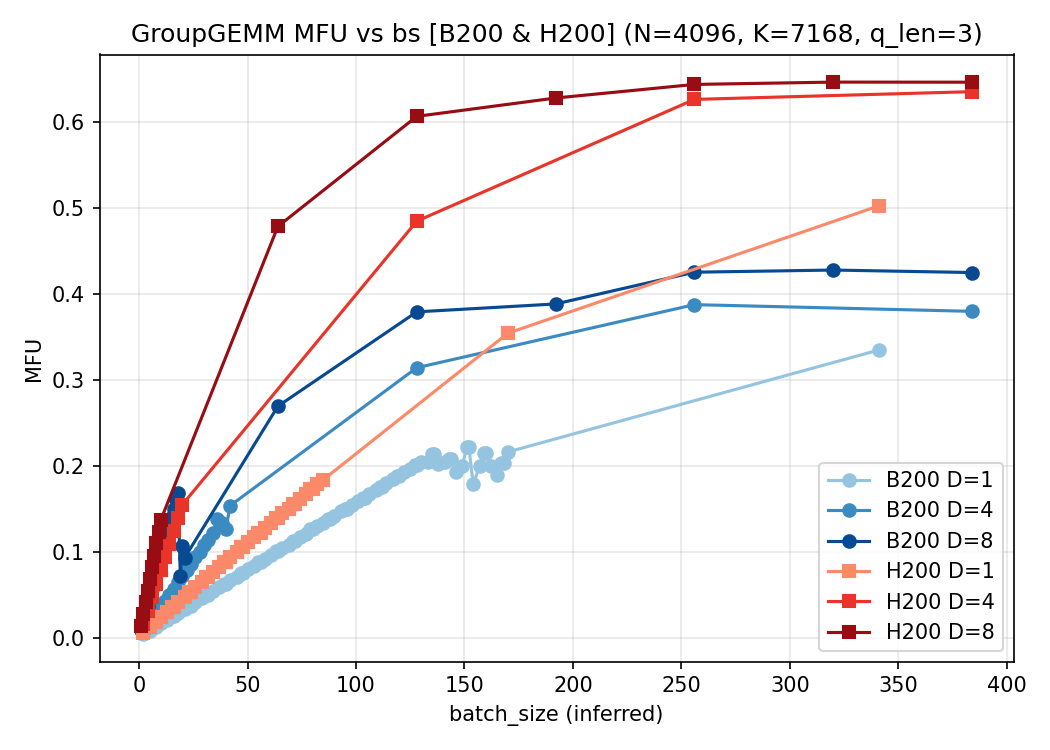
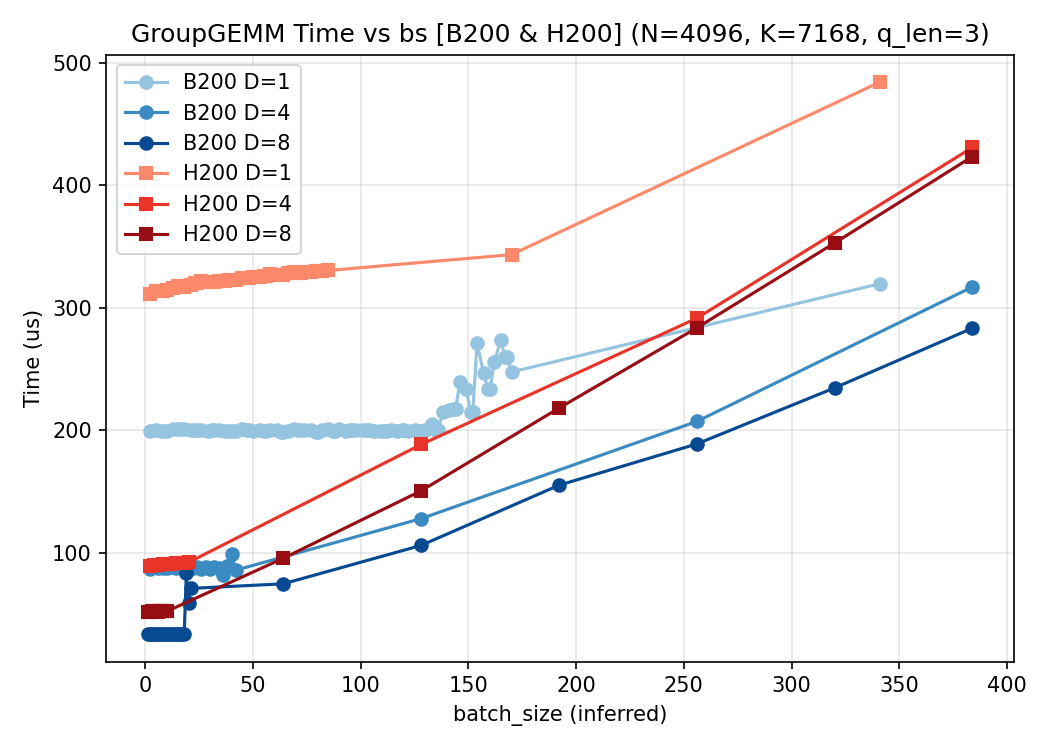
$Q=4$:
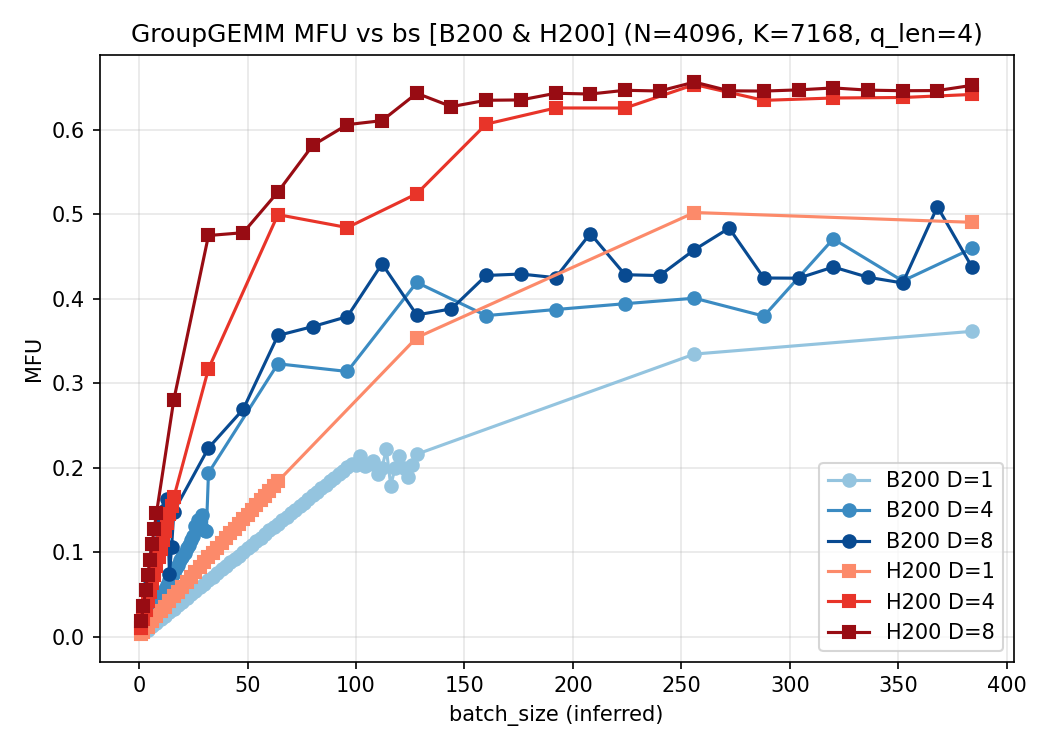
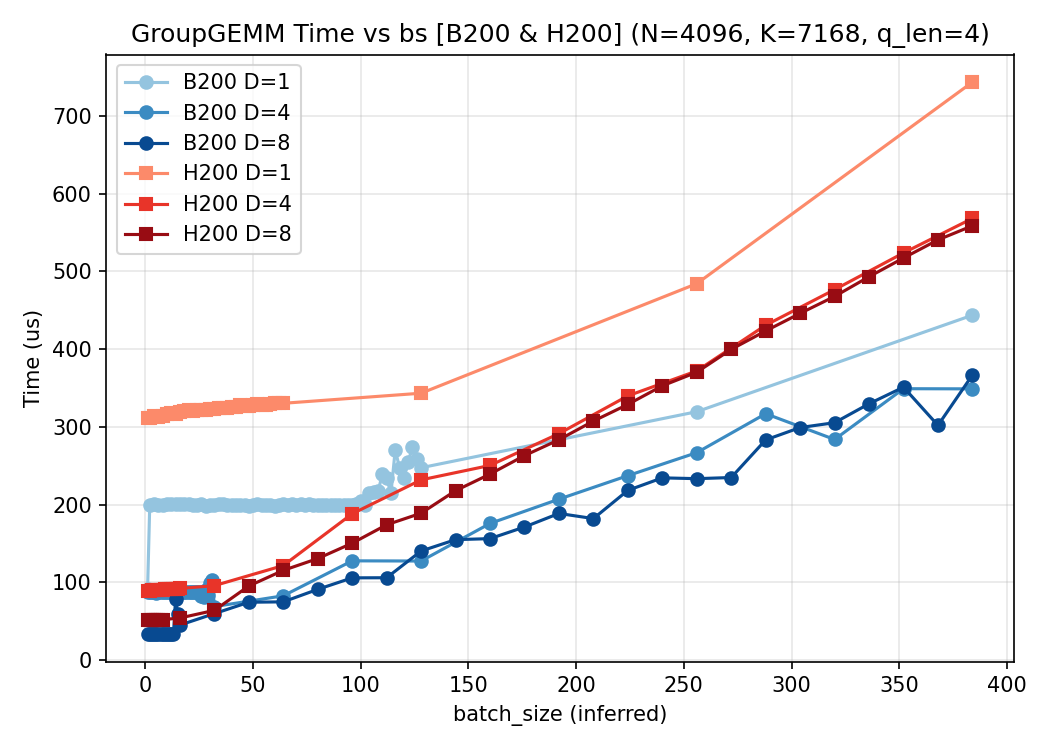
3. 结论
本文围绕解码阶段的 GroupGEMM这个算子,从上至下地建立了从 sglang 启动参数到算子入参的明确映射,并从理论和实践两方面进行了验证。可以看到,在每种情况下,都是 D 越大的曲线,耗时和 MFU 越好,这是可以理解的:num_groups几乎都是一个常量,而 D 越大,会导致 m 越大,从而提高算子的利用率。所以,如果从实际部署的角度考虑,在解码阶段,部署更多的数据并行实例有助于算子耗时减少,但同时,机器间的通信耗时就会成为新的瓶颈,需要两者之间做一个取舍。考虑到目前硬件的不同实现, 在 B200 上的groupgemm 算子的性能远不如 H200 上的实现,所以可以看到,B200 的单机 8 卡的 groupgemm 耗时大约是 H200 的一半,这个是符合预期的,而 4 机 32 卡时,耗时甚至和 H200 一致,导致吞吐上不去,没有拉开差距,考虑到通信开销,这一部分的开销可能还大于 H200. 显然是不可接受的。所以目前来看,B200 上的解码阶段的部署,还是以单机为主。(但是能接受的批处理的数目又要减少了)。